들어가며
대용량 데이터를 다룰 때 인덱스의 역할은 매우 중요하다. 인덱스를 통해 빠른 데이터 검색이 가능하기 때문이다.
인덱스는 한 개 또는 두 개 이상의 컬럼에 복합적으로 설정할 수 있는데, 두 개 이상의 컬럼으로 구성된 인덱스를 다중(복합) 컬럼 인덱스라고 한다.
본 글은 다중 컬럼 인덱스를 설계하며 겪은 문제 상황과 이에 대한 해결책을 정리한 글이다.
본론에 앞서 PostgreSQL에서의 쿼리 실행 방식과 EXPLAIN 명령어에 대해서 간단히 살펴보자.
Planner/Optimizer
SQL Query는 다양한 방식으로 실행될 수 있다. (Scan, Join 방식 등) PostgreSQL의 Optimizer는 CBO(Cost Based Optimizer)로 파라미터 및 통계 정보를 바탕으로 이러한 다양한 실행 계획에 대한 비용을 계산하여 최종적으로 가장 빠르게 실행될 것으로 예상되는 방식을 선택한다. 즉, 최적의 실행 계획을 만드는 역할을 한다.
EXPLAIN
위에서 Planner가 만든 실행 계획은 EXPLAIN 명령을 통해 볼 수 있다. EXPLAIN을 사용하면 테이블을 어떻게 스캔할 것인지, 조인이 사용될 경우 어떠한 조인 알고리즘을 사용할 것인지, 예상되는 결과 및 비용 등을 보여준다.
여기서 눈여겨볼 점은 실제 쿼리가 실행되지 않는다는 것이다. (ANALYZE 옵션을 사용하면 실제 쿼리가 실행된다)
그렇다면 테이블에 접근하지도 않았는데 어떻게 결과를 예상할 수 있을까?
PostgreSQL은 테이블에 대한 각종 통계 정보를 수집한다. 여기에는 컬럼의 평균 크기, 자주 등장하는 값, 빈도수 등이 포함된다. Planner는 이러한 통계 자료를 통해 비용을 계산하여 테이블에 접근하기도 전에 효율적인 실행 계획을 만들어내는 것이다.
문제 상황
먼저 테이블의 구성을 살펴보자.
(userNum, gameId)가 primary key로, (versionMajor, versionMinor)가 Index로 설정되어 있다.
CREATE TABLE game (
userNum integer,
gameId integer,
versionMajor integer,
versionMinor integer,
...,
primary key (userNum, gameId)
);

문제가 되는 쿼리는 아래와 같다. 인덱스로 설정된 두 컬럼의 값이 특정된 조건을 만족하는 데이터의 수를 보여주는 쿼리이며 해당되는 데이터의 개수는 0개다. 쿼리 실행 시간은 약 37초로 해당되는 데이터가 없음에도 인덱스를 타지 않은 것으로 보인다.
SELECT * FROM game
WHERE "versionMajor" = 15 AND "versionMinor" = 0;
인덱스를 타지 않는 이유는 여러가지가 있을 수 있다. 1) 인덱스를 건 순서와 조건 순서가 다르거나 2) 조건에 해당되는 데이터가 많아 Full Scan이 더 효율적이거나 3) 함수나 연산자 등의 사용으로 인덱스 컬럼이 변형되는 경우 ... 등 다양한 이유가 있지만 쿼리만 봤을 때는 문제가 딱히 없어 보인다.
그럼 이제 실행 계획을 살펴보자.
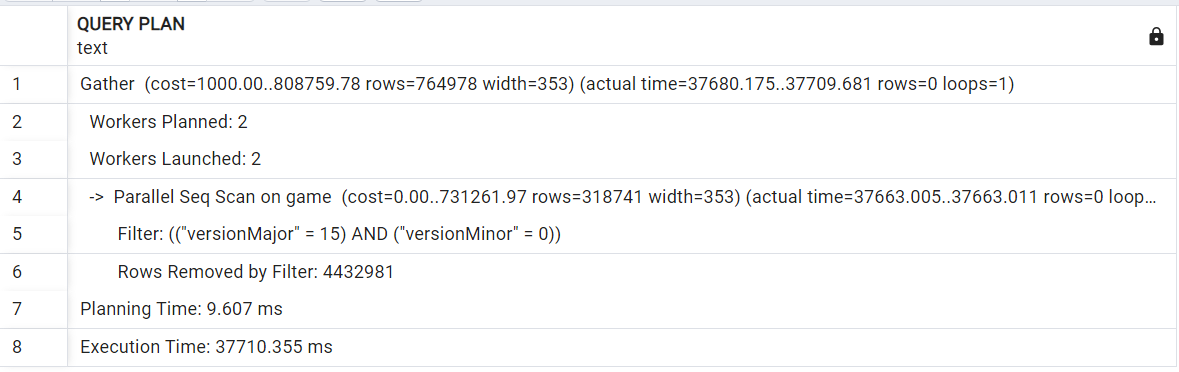
실행 계획에서 각 키워드가 의미하는 바는 아래와 같다.
(cost=1000.00..808759.78 rows=764978 width=353)
cost = 예상되는 cost
rows = 예상되는 row의 수
width = 예상되는 row당 평균 byte 수
(actual time=37680.175..37709.681 rows=0 loops=1)
actual time = 쿼리가 실제로 실행되는 시간
rows = 실제 결과 row의 수
loops = node가 반복된 횟수
실행 계획을 해석해보면 실제 테이블에는 0건의 데이터가 있지만 플래너는 764,978건의 데이터가 존재한다고 판단, 데이터가 많아 Index Scan 보다 Seq Scan을 수행한 것이다.
플래너는 왜 데이터가 764978건이나 있다고 판단했고 이 숫자는 어디서 나온 것일까?
원인을 추측해보자
위에서 간단하게 설명했듯이 플래너는 통계 정보를 바탕으로 비용을 계산한다. 그럼 플래너가 실행 계획을 만들 때 사용하는 통계 자료를 확인해보자.
PostgreSQL에서는 pg_statistic 카탈로그에 저장된 통계 자료에 접근할 수 있도록 pg_stats라는 뷰 테이블을 제공한다.
SELECT attname, most_common_vals, most_common_freqs
FROM pg_stats
WHERE tablename = 'game' AND attname LIKE 'version%';

| versionMajor | frequency |
| 15 | 8.31% |
| 16 | 17.68% |
| 17 | 18.58% |
| 18 | 10.29% |
| 19 | 29.54% |
| 20 | 7.53% |
| 21 | 8.04% |
| versionMinor | frequency |
| 0 | 69.19% |
| 1 | 23.22% |
| 2 | 7.58% |
통계 자료를 보면 versionMajor와 versionMinor에 대한 정보를 개별로 저장하고 있다. 즉, 두 컬럼이 동시에 특정된 값에 대한 통계 자료는 존재하지 않는다. 그렇다면 해당 통계를 얻기 위해서는 별도의 가공 과정이 필요하다고 예상할 수 있다.
다시 돌아가서 처음에 데이터 분포를 알기 위해 실행했던 group by절에 대한 실행 계획도 확인해보자.

실제 두 컬럼의 조합은 10개
플래너가 예상한 두 컬럼의 조합은 21개
즉, 플래너는 두 컬럼이 가질 수 있는 경우의 수 각각 7개, 3개를 곱한 21개의 조합이 나올 수 있다고 판단하고 있는 것이다.
그렇다면 두 컬럼에 대한 통계를 얻기 가장 쉬운 방법은 단순히 두 확률의 값을 곱하는 것이다.
versionMajor가 15인 8.31%에 versionMinor가 0인 69.19%를 곱한 값을 전체 데이터의 수 13,298,943개에 곱하면
764,647개로 플래너가 예측한 값(764,978)과 거의 같다.
따라서, 플래너는 versionMajor와 versionMinor에 대한 각각의 통계를 곱한 값으로 추정한다고 추측할 수 있다.
(실제로 그렇게 작동하는 듯하다 참고자료 3번)
이를 해결하기 위해서는 플래너가 올바른 통계 자료를 사용하도록 multi column index에 대한 통계를 직접 만들어줘야 한다.
통계를 만들어보자
create statistics로 통계에 대해 정의를 하고 analyze를 통해 통계 자료를 수집한다.
CREATE STATISTICS version_statistics ON "versionMajor", "versionMinor" FROM game;
ANALYZE game;
직접 생성한 통계 정보는 pg_stats_ext에 저장된다.
아래 쿼리를 통해 확인해보자.
select statistics_name, attnames, most_common_vals, most_common_freqs from pg_stats_ext;
pg_stats_ext를 살펴보면 처음 테이블에 들어있던 10개 그룹에 대한 통계가 만들어졌음을 확인할 수 있다.
이제 처음의 쿼리를 통해 실행 계획을 다시 살펴보면 Planner가 통계를 제대로 활용하고 있다.


결론
- PostgreSQL에서 Multi-Column Index를 설정하는 것은 cross-column에 대한 통계를 자동적으로 생성해주지 않는다.
- 이는 플래너가 비효율적인 Query Plan을 설계하도록 유도할 수 있다.
- 따라서 플래너가 최적의 Query Plan을 설계하도록 통계를 직접 만들어줘야 한다.
- 항상 쿼리 플랜을 살펴보자.
참고자료
- PostgreSQL: Documentation: 16: 14.2. Statistics Used by the Planner
- PostgreSQL: Documentation: 16: 76.2. Multivariate Statistics Examples
- Optimization issues: Cross column correlation | CYBERTEC PostgreSQL | Services & Support (cybertec-postgresql.com)
- Postgresql - Create multicolumn Index - statistics created or not - Stack Overflow
'데이터베이스' 카테고리의 다른 글
| [PostgreSQL] Materialized View (with NestJS + TypeORM) (0) | 2024.08.28 |
|---|